5 Basic Concepts
This chapter covers the basic concepts that you’ll need to understand in order to use CloudLab.
5.1 Profiles
A profile encapsulates everything needed to run an experiment. It consists of two main parts: a description of the resources (hardware, storage, network, etc.) needed to run the experiment, and the software artifacts that run on those resources.
The resource specification is in the RSpec format. The RSpec describes an entire topology: this includes the nodes (hosts) that the software will run on, the storage that they are attached to, and the network that connects them. The nodes may be virtual machines or physical servers. The RSpec can specify the properties of these nodes, such as how much RAM they should have, how many cores, etc., or can directly reference a specific class of hardware available in one of CloudLab’s clusters. The network topology can include point to point links, LANs, etc. and may be either built from Ethernet or Infiniband.
The primary way that software is associated with a profile is through
disk images. A disk image (often just called an
“image”) is a block-level snapshot of the contents of a real or virtual
disk—
Profiles come from two sources: some are provided by CloudLab itself; these tend to be standard installations of popular operating systems and software stacks. Profiles may also be provided by CloudLab’s users, as a way for communities to share research artifacts.
5.1.1 On-demand Profiles
Profiles in CloudLab may be on-demand profiles, which means that they are designed to be instantiated for a relatively short period of time (hours or days). Each person instantiating the profile gets their own experiment, so everyone using the profile is doing so independently on their own set of resources.
5.1.2 Persistent Profiles
CloudLab also supports persistent profiles, which are longer-lived (weeks
or months) and are set up to be shared by multiple users. A persistent profile
can be thought of as a “testbed within a testbed”—
An instance of a cloud software stack, providing VMs to a large community
A cluster set up with a specific software stack for a class
A persistent instance of a database or other resource used by a large research community
Machines set up for a contest, giving all participants access to the same hardware
An HPC cluster temporarily brought up for the running of a particular set of jobs
A persistent profile may offer its own user interface, and its users may not necessarily be aware that they are using CloudLab. For example, a cloud-style profile might directly offer its own API for provisioning virtual machines. Or, an HPC-style persistent profile might run a standard cluster scheduler, which users interact with rather than the CloudLab website.
5.2 Experiments
See the chapter on repeatability for more information on repeatable experimentation in CloudLab.
An experiment is an instantiation of a profile. An experiment uses resources, virtual or physical, on one or more of the clusters that CloudLab has access to. In most cases, the resources used by an experiment are devoted to the individual use of the user who instantiates the experiment. This means that no one else has an account, access to the filesystems, etc. In the case of experiments using solely physical machines, this also means strong performance isolation from all other CloudLab users. (The exceptions to this rule are persistent profiles, which may offer resources to many users.) Note that members of the project that the experiment belongs to typically also have full (root) access to the resources in that experiment.
Running experiments on CloudLab consume real resources, which are limited. We ask that you be careful about not holding on to experiments when you are not actively using them. If you are are holding on to experiments because getting your working environment set up takes time, consider creating a profile with one or more custom disk images that captures your environment.
The contents of local disks on nodes in an experiment are considered
ephemeral—
All experiments have an expiration time. By default, the expiration time is short (a few hours), but users can use the “Extend” button on the experiment page to request an extension. A request for an extension must be accompanied by a short description that explains the reason for requesting an extension, which will be reviewed by CloudLab staff. You will receive email a few hours before your experiment expires reminding you to copy your data off or request an extension.
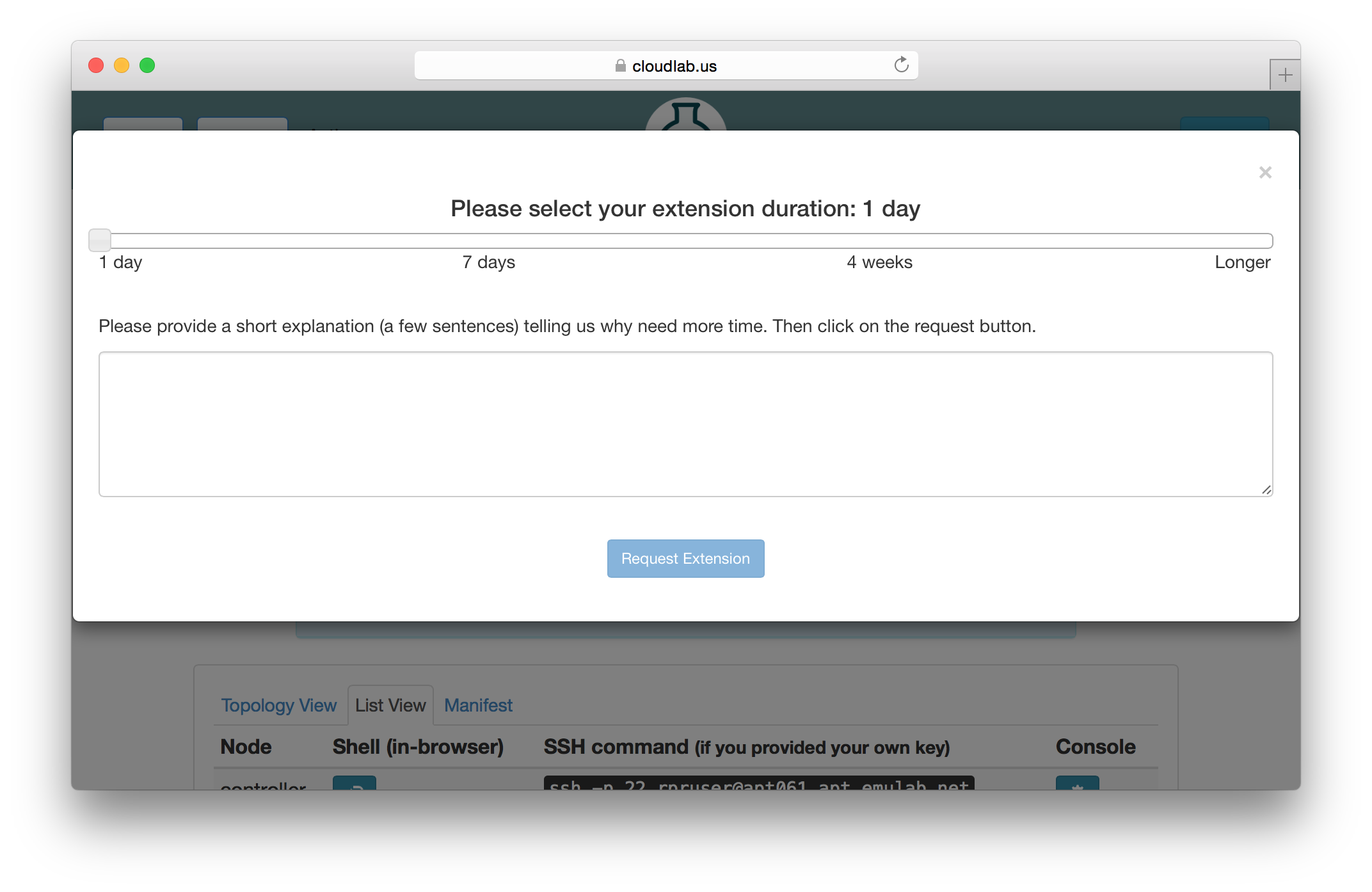
5.2.1 Extending Experiments
If you need more time to run an experiment, you may use the “Extend” button on the experiment’s page. You will be presented with a dialog that allows you to select how much longer you need the experiment. Longer time periods require more extensive appoval processes. Short extensions are auto-approved, while longer ones require the intervention of CloudLab staff or, in the case of indefinite extensions, the steering commitee.
5.3 Projects
Users are grouped into projects. A project is, roughly speaking, a group of people working together on a common research or educational goal. This may be people in a particular research lab, a distributed set of collaborators, instructors and students in a class, etc.
A project is headed by a project leader. We require that project leaders be faculty, senior research staff, or others in an authoritative position. This is because we trust the project leader to approve other members into the project, ultimately making them responsible for the conduct of the users they approve. If CloudLab staff have questions about a project’s activities, its use of resources, etc., these questions will be directed to the project leader. Some project leaders run a lot of experiments themselves, while some choose to approve accounts for others in the project, who run most of the experiments. Either style works just fine in CloudLab.
Permissions for some operations/resources depend on the project that they belong to.
Currently, the only such permission is the ability to make a profile visible onto to the owning project. We expect to introduce more project-specific permissions features in the future.
5.4 Physical Resources
Users of CloudLab may get exclusive, low-level (root) control over physical machines. When allocated this way, no layers of virtualization or indirection get in the way of the way of performance, and users can be sure that no other users have access to the machines at the same time. This is an ideal situation for repeatable research.
Physical machines are re-imaged between users, so you can be sure that your physical machines don’t have any state left around from the previous user. You can find descriptions of the hardware in CloudLab’s clusters in the hardware chapter.
5.5 Virtual Machines
While CloudLab does have the ability to provision virtual machines (using the Xen hypervisor), we expect that the dominant use of CloudLab is that users will provision physical machines. Users (or the cloud software stacks that they run) may build their own virtual machines on these physical nodes using whatever hypervisor they wish. However, if your experiment could still benefit from use of virtual machines (e.g. to form a scalable pool of clients issuing requests to your cloud software stack), you can find more detail in the advanced topics section.